


If you are reading this, you probably already know the problem. You need to create efficient ways to automate your workflows using the documents you have. You rely on PDFs, scanned invoices, contracts, engineering drawings, and medical records, yet the gap between the data you have and the data your AI systems can actually use is exactly where intelligent document processing comes in.
We built this guide because our customers kept asking us to compare options. Rather than pointing them to the same recycled listicles that rank whoever wrote them at #1, we decided to do something more useful. A genuine breakdown of 15 platforms, what they are good at, where they fall short, and how to think about choosing between them.
Why? We all know that Gartner and IDC estimate that 80 to 90 per cent of enterprise data remains locked in unstructured formats. That is not a new statistic. What is new is the acceleration of investment to fix it. AI and AI-driven workflows are changing the game, making it possible to move from raw, unstructured documents to usable, structured data at a speed and scale that wasn't feasible even two years ago.
A recent AIIM/Deep Analysis survey of 600+ organisations found that 65% of companies are actively ramping up their document processing initiatives. When two-thirds of the market is moving in the same direction at the same time, the platform you choose now will shape everything you build next.

At its core, AI document processing is about turning messy, unstructured documents into clean, structured data that machines can actually work with. It uses machine learning, computer vision, NLP, and increasingly large language models to do what used to require rooms full of people: reading documents, understanding their meaning, and extracting the information that matters. What separates modern platforms from the OCR tools of a decade ago is depth.
Today's systems do not just read text. They understand structure, classify documents on the fly, score their own confidence, and feed results directly into downstream workflows. Here are the five capabilities that define the category:
This distinction matters because many enterprise teams still think of document processing as "better OCR." It is not.
OCR reads characters from images and converts pixels to text. That is where it stops. AI document processing operates at a fundamentally different level, and understanding the gap is critical to evaluating platforms correctly.

In practice, three differences stand out:
While each vendor implements things differently, most platforms follow the same four-stage pipeline.

The first two stages (ingestion and extraction) are where most platforms compete on features. But stages three and four are where production systems succeed or fail.
Confidence scoring determines whether you can automate at all, and integration depth determines how much engineering effort sits between extraction and business value. A platform that nails stages one and two but leaves you to build three and four from scratch may end up costing more in engineering time than it saves in extraction accuracy.
What follows is a flat list, not a ranking. We reviewed each platform against public documentation, analyst reports, customer references, and (where applicable) our own experience working alongside them in production environments.
Meibel is an AI orchestration platform that treats document processing as one step in a larger pipeline, not the destination. The platform manages Context (semantic segmentation at ingest), Control (deterministic workflow orchestration), and Confidence (output scoring across 14 dimensions before anything reaches production). It connects to any LLM without lock-in, and replaces the brittle combination of DIY tooling, RAG frameworks, and glue code that most teams end up building. SaaS, private cloud, or on-premises.
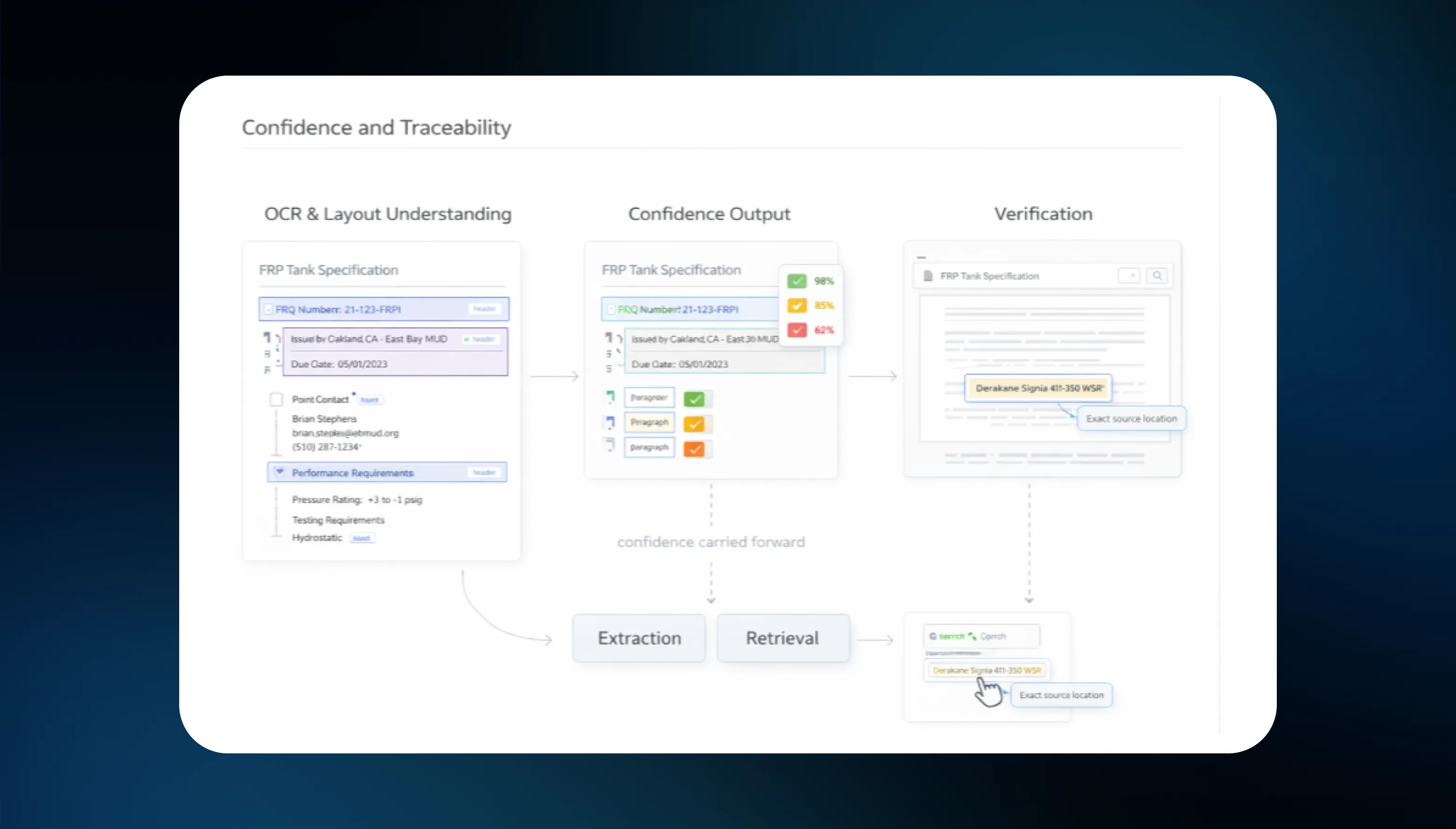
To see what this looks like in practice, in construction, where documents are notoriously complex, SpecBooks used Meibel to automate quoting from architectural blueprints, replacing thousands of lines of custom Textract + Bedrock code and achieving a 400% increase in bid volume. In strategic consulting, Toffler Associates built a self-service foresight product where low-confidence results automatically route to human analysts for review.
If longevity counts for anything in this space, ABBYY has the strongest claim. Founded in 1989, the company has been doing document processing longer than most of its competitors have existed. The Vantage Marketplace ships with 150+ pre-trained models, and Vantage 3.0 (launched January 2026) adds direct generative AI integration. One of five Leaders in the inaugural 2025 Gartner Magic Quadrant for IDP.
Founded in 2014, Hyperscience stands out for one capability most competitors simply do not have: handwriting recognition. The proprietary ORCA model handles structured, semi-structured, unstructured, and handwritten documents with human-in-the-loop validation built in. Named a Gartner MQ Leader with the furthest placement for completeness of vision. FedRAMP High authorized since December 2024.
One of the largest dedicated IDP vendors globally, Tungsten Automation has been in the business since 1985 and employs roughly 2,200 people. After acquiring Ephesoft in 2022, the TotalAgility platform now combines IDP with full workflow orchestration, AI copilots, and 140+ connectors. Named a Gartner MQ Leader, and notably achieved full FedRAMP High ATO in March 2026, making it one of very few IDP platforms with that designation.
For teams already building on Google Cloud, Document AI is the natural fit. It offers approximately 18 processors, including specialized pre-trained models, and the Layout Parser v1.6 (powered by Gemini 3 Flash, launched in preview January 2026) brings generative AI directly into the extraction pipeline. Handwriting recognition works across 50+ languages.
If cost is the primary constraint, Amazon Textract is hard to beat. AWS's fully managed service handles text detection, forms, tables, queries, signatures, and lending analysis at scale, and the pricing starts lower than anything else on this list.
Formerly Form Recognizer, Azure AI Document Intelligence is Microsoft's answer to the document processing challenge. It ships prebuilt models for invoices, receipts, IDs, and tax forms, alongside custom templates and neural models. A 40% price cut on custom extraction in June 2024 made it significantly more competitive, and the free tier offers 500 pages/month.
For pure extraction accuracy, Reducto is making a strong case. The vision-first, multi-pass agentic OCR self-corrects across passes, and the four-endpoint API (Parse, Extract, Split, Edit) is clean and developer-friendly.
When the challenge is format breadth rather than extraction depth, Unstructured is the go-to. It handles 64+ file types, converting everything into structured JSON for LLM and RAG consumption. It ships with 30+ source connectors and 1,250+ pre-built pipelines. SOC 2 Type II certified.
If you are already building with LlamaIndex, LlamaParse is the natural parsing layer. v2 introduced a 50% price reduction, support for 130+ file formats, and agentic OCR, all optimized specifically for LLM consumption downstream.
Founded in 2020, Sensible takes a clever hybrid approach: LLMs handle document variation and ambiguity, while deterministic layout rules lock down consistency for known document types. The result is 150+ pre-built configurations that work reliably for loan applications, receipts, pay stubs, and IDs.
Co-founded by Douwe Kiela and Amanpreet Singh, who co-authored the seminal 2020 RAG paper at Meta AI, Contextual AI brings academic depth to production AI. The company offers a Document Parser with confidence scoring, a RAG 2.0 engine, and an Agent Composer for multi-step orchestration (launched January 2026). Distribution through Snowflake and Google Cloud Marketplace.
With 10,000+ active use cases, Nanonets has built significant traction in the SMB and mid-market segments. The platform goes beyond extraction with agentic workflows: classify, extract, validate, and push directly to Salesforce, SAP, or QuickBooks. A strong partner channel provides implementation support across industries.
Rossum has carved out a strong niche in transactional documents. Founded in 2017 with 450+ enterprise deployments, the platform is one of the first IDP vendors to achieve ISO/IEC 42001:2023 certification for AI management systems. The proprietary Rossum Aurora engine handles template-free recognition, which means it processes invoices and POs from new vendors without anyone configuring templates first.
For banking and insurance teams specifically, Docsumo offers a purpose-built solution. Founded in 2019, the platform uses an agentic approach where AI agents handle the full workflow: classification, extraction, validation, and escalation.
Most vendor content focuses on accuracy benchmarks and polished demos. That is fine for initial evaluation, but it misses the factors that actually determine success in production. Here is what we have learned working with teams that have moved past the proof-of-concept stage.
Every vendor shows their best results on their best documents. In production, you encounter coffee stains, handwritten annotations in the margins, mixed languages, rotated pages, and layouts that nobody anticipated during setup. The question is not "what accuracy does the vendor claim?" The question is: what happens when confidence drops below your threshold? Platforms that score confidence at the field level give you a mechanism to catch failures automatically. Platforms that do not leave you blind.
Extraction is often the easy part. The expensive part is everything you build around it: preprocessing, chunking strategies, retrieval logic, validation rules, error handling, retry logic, and the integration code that connects extraction outputs to your actual business systems. Many teams discover that the API cost per page is a fraction of their real spend.
If a platform cannot tell you how confident it is in each extraction, at the field level, with thresholds you can act on, then every output requires a human to verify it. That defeats the purpose of automation. This is exactly the problem that runtime confidence scoring is designed to solve: measuring trust in AI outputs before they reach production, not after something breaks.
After working with dozens of teams evaluating document processing options, we have noticed the same six questions keep surfacing. They tend to narrow the field faster than any feature comparison matrix.
Ready to start your AI journey? Contact us to learn how Meibel can help your organization harness the power of AI, regardless of your technical expertise or resource constraints.


AI document processing uses machine learning, computer vision, NLP, and large language models to extract, classify, and validate data from unstructured documents. It matters because the vast majority of enterprise data (80-90% according to Gartner and IDC) sits in formats that AI systems cannot use directly. Without reliable document processing, every downstream workflow, from RAG to agent orchestration, operates on incomplete or inaccurate context.
Intelligent document processing is the industry term for AI-powered systems that go beyond traditional OCR. Where OCR reads characters, IDP understands structure, classifies documents, scores confidence, and integrates with business workflows. The category matured significantly in 2025 when Gartner published its first-ever Magic Quadrant for IDP, evaluating 18 vendors and establishing formal criteria for the space.
OCR converts image text to machine-readable characters. AI document processing builds on that foundation by adding structural understanding (tables, headers, sections), semantic extraction (specific entities and data points), automatic classification, field-level confidence scoring, and direct workflow integration. In practical terms: OCR gives you text. AI document processing gives you structured, scored, actionable data.
Financial services hold the largest share of the intelligent document processing market, followed by insurance, government, and healthcare (the fastest-growing vertical). Legal and manufacturing are also seeing significant adoption. One area that remains notably underserved is construction, where document complexity is extreme and most vendors have not invested in purpose-built capabilities. That gap is one reason we built Meibel's construction document processing pipeline, and why the SpecBooks case study resonates so strongly with teams in similar industries.
The range is enormous. Cloud APIs like Amazon Textract start at $0.0015 per page for basic text detection, though structured extraction features like forms and tables push that to $0.05–$0.07 per page. Enterprise platforms like Hyperscience start around $50K per year before per-page processing fees. But per-page pricing only tells part of the story.
Document processing produces the structured context that retrieval-augmented generation and AI agents need to operate reliably. If the extraction is inaccurate or the structure is lost, RAG returns the wrong context and agents make decisions on bad data. This is why platforms that treat extraction as step one in a confidence-scored pipeline, rather than an isolated tool, tend to deliver better production outcomes. It is also why we built Meibel as an orchestration platform rather than a standalone parser: the value is in the pipeline, not just the first stage.
Agentic document processing is an emerging approach where AI agents autonomously classify, extract, validate, and route documents without human intervention at each step. Unlike traditional template-based IDP, agentic systems handle novel document types without pre-configured rules. Several platforms on this list use agentic approaches, including Reducto.ai (agentic OCR), Nanonets, Docsumo, and Hyland.
Dimitar Vladimiroski is a Technical Analyst at Meibel, where he turns complex data into clear, actionable insights. With a sharp analytical mindset and a passion for problem-solving, he helps drive smarter decisions through technical expertise and attention to detail.
REQUEST A DEMO
See how Meibel delivers the three Cs for AI systems that need to work at scale.

