Document intelligence
Meibel turns complex documents into AI-ready context: structure preserved, confidence scored, every answer traceable to its source.




Why you need meibel
OCR gives you characters. Chunking gives you fragments. Neither gives you the structure that decides whether the answer is right. When a table becomes a paragraph, the numbers are still there but the relationships between them are gone.
Table structure is flattened into text. Rows, columns, and relationships between values disappear. A table rendered as a paragraph is useless for any downstream query.
A 600-page legal document contains covenants that reference other covenants. None of that resolves when files are processed in isolation.
COAs come in thousands of formats from various suppliers. The fields that matter (batch number, test method, result, specification) vary by document. Generic extraction misses domain-specific fields entirely.

Most platforms stop at extraction. Document Intelligence starts there.
Document Intelligence does not treat documents as bags of text. It understands structure: headers scope sections, captions describe tables, footnotes relate to claims, charts contain data that is not in the text. Every element gets the processing path it needs.

Document Intelligence does not stop at the boundary of one file. When your documents reference each other, cite each other, or share structure, those connections are extracted and made traversable. Your document estate becomes a connected knowledge base, not a filing cabinet.

A single PDF can produce text chunks for semantic search, tables for SQL queries, metadata for filtering, and citations for graph traversal. All three retrieval modes are available simultaneously. An agent can find relevant content by meaning, query precise values from extracted tables, and follow citation chains to referenced documents in a single reasoning step.

Try Meibel
What you build on it, agents that extract and validate, workflows that route and escalate, applications that answer and prove, runs on the Meibel platform.




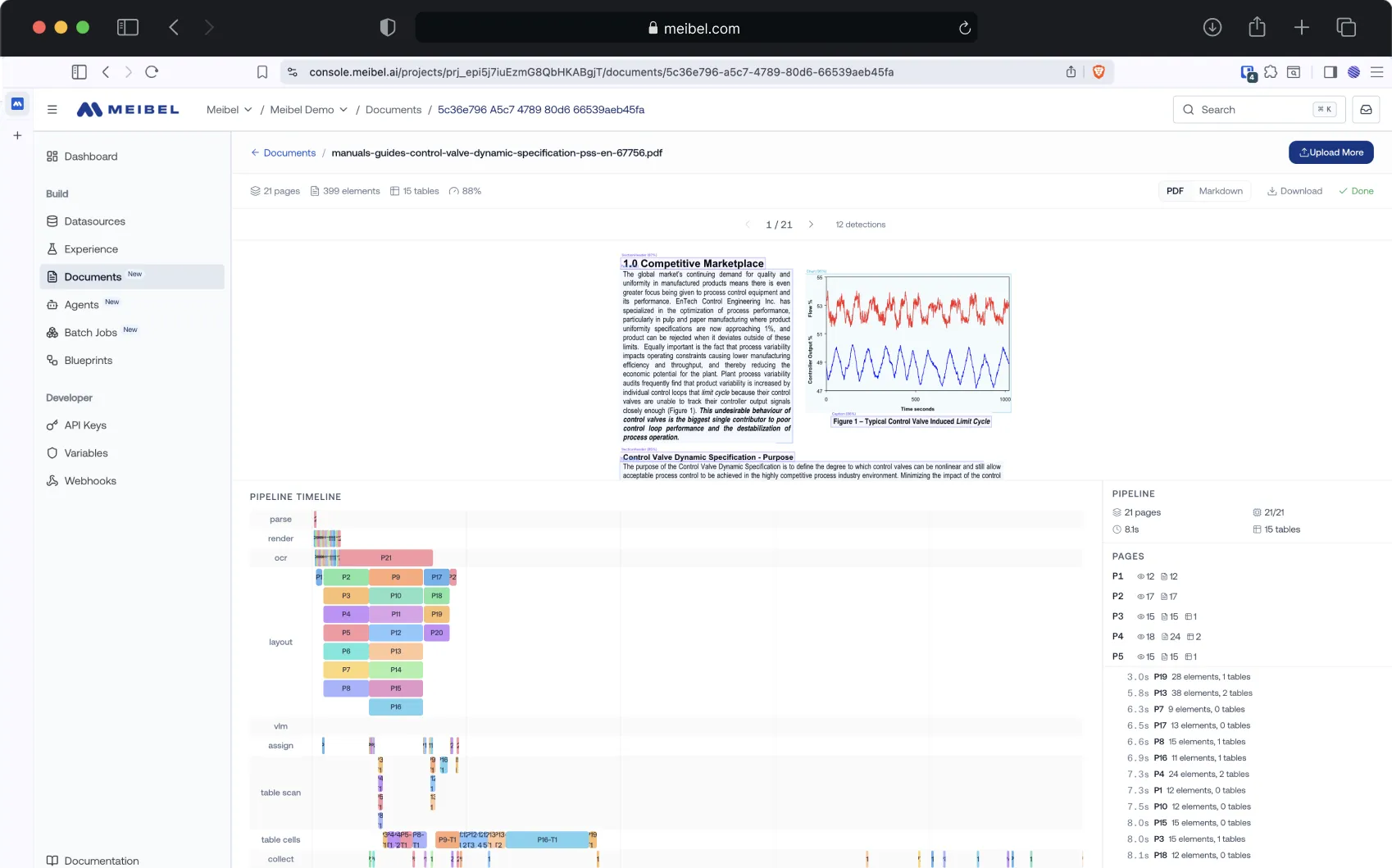
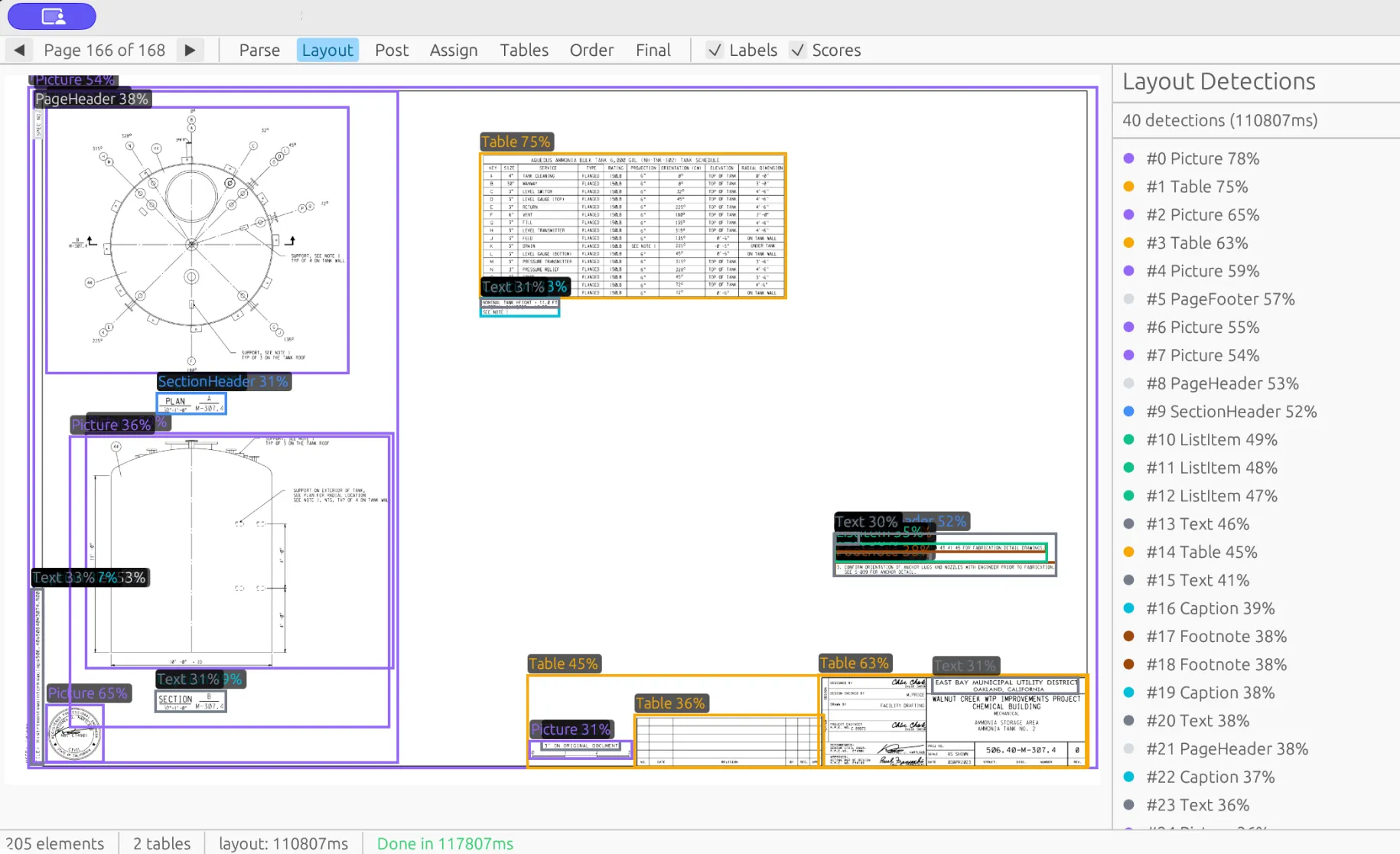
Detects headers, paragraphs, tables, images, lists, captions, page layout, reading order, and spatial relationships. Multi-column documents are read in the correct order. A section header scopes everything beneath it. A caption is linked to its table.
Tables stay structured. Charts are processed through vision models to extract data points. Scanned tables get OCR plus schema inference. Diagrams get visual descriptions. Photographs get semantic descriptions.
Seven built-in metadata models extract the fields your industry uses. E.g. insurance: policy_number, effective_date, carrier, coverage_type. Legal: case_number, jurisdiction, filing_date, parties.
Every extracted value traces back to the exact region on the exact page of the original document. Bounding box coordinates identify the precise source location. Click a data point, see the source. No black boxes.
Six scoring modules evaluate every output: Coherence, Completeness, Correctness, Faithfulness, Relevance, and OCR Confidence. Scores drive routing: high-confidence outputs move forward automatically, low-confidence outputs trigger retry, review, or escalation.
Combine semantic search for meaning, SQL over extracted tables for precise numerical answers, and graph traversal across references, versions, and document relationships. All three modes available simultaneously on the same corpus.


Who is it for?
Drop in any file. The system detects the format, analyzes layout and reading order, and processes every element according to its type - automatically, with no configuration needed.
25+ formats supported: PDF, DOCX, PPTX, HTML, images, emails, spreadsheets, JSON, CSV, archives, and more
Layout understood: headers, paragraphs, tables, images, lists, captions, and their spatial relationships
Every element processed correctly: tables stay structured, handwriting gets read, mixed content handled automatically

Every extracted element links back to its exact location in the source document, and every field is pulled according to what the document actually is - not a generic template.
Bounding box coordinates identify the precise region on the precise page
Seven built-in metadata models: insurance, legal, medical, manufacturing, construction, bibliography, and custom
Custom extraction schemas can be defined per data source, industry, or workflow

Every extraction is scored across multiple independent dimensions: Coherence, Completeness, Correctness, Faithfulness, Relevance, and OCR Confidence.
High-confidence outputs move forward.
Low-confidence or critical fields trigger retry, review, or escalation.



Use Cases
One data corpus. Multiple experiences. Meibel lets you process your data once and build as many solutions as you need on top, without reprocessing or rebuilding your pipeline.



Try it live
Document Intelligence is free to start. Upload a document and see what production-grade document understanding looks like.

Document Intelligence is the document understanding layer that turns complex files into structured, queryable, scored, and traceable context. It understands layout, preserves tables, classifies images, extracts domain-specific metadata, scores confidence on every output, and makes the result available through semantic search, SQL, and graph traversal.
OCR reads text. Document Intelligence preserves layout, tables, images, metadata, element relationships, confidence, and provenance so the extracted output can be used reliably downstream. Every element gets the processing path it needs: tables stay structured, charts become data, handwriting gets read, diagrams get described.
Basic RAG chunks and retrieves text. Document Intelligence combines structure-preserving ingest, semantic retrieval, SQL over extracted data, graph traversal across document relationships, and confidence scoring. An agent can use all three retrieval modes in a single reasoning step.
Cloud document AI services parse individual files. They do not build corpus-level connections, consolidate schemas across documents, construct reference graphs, or integrate confidence scoring into execution routing. Meibel does all of that and includes the retrieval layer so you do not need to assemble a separate stack.
Yes. Tables are preserved as structured, queryable data. Image-based tables get OCR plus schema inference. Charts are processed through vision models to extract data points. Diagrams get visual descriptions. Handwriting, stamps, and annotations are handled automatically.
Yes. Seven built-in metadata models cover insurance, legal, medical, product/manufacturing, construction, bibliography, and custom domains. Teams can also define custom extraction schemas per data source, industry, workflow, or domain need.
Low-confidence outputs can trigger retry, re-extraction, review, escalation, or blocking based on field importance and workflow rules. Reviewers see the original document alongside extracted data with bounding box overlays and field-level status indicators.
Every extracted value traces back through the pipeline to the source document, page, and exact region where the evidence came from. Bounding box coordinates identify the precise location. At the corpus level, the citation graph traces relationships between documents: which documents reference which, which components were derived from which sources.
Document Intelligence is free to start. Production usage is billed per page, starting at $0.03/page with volume pricing available. LLM costs are passed through at cost with no markup. Contact us for volume pricing. (Confirm pricing with pricing team before publish.)
Minutes for your first document parse. Days for schema configuration and extraction tuning on your specific document types. One to a few weeks for full production deployment depending on output complexity. POC at no charge to ensure product fit.
Meibel supports SaaS, bring-your-own-cloud (data plane in your environment), and on-premises deployment. For BYOC, documents never leave your environment. Client-side processing for regulated industries where documents cannot leave the user's device is on the roadmap.
AI builders, platform teams, data teams, product operations, risk and compliance teams, and enterprises building AI workflows on complex document collections.