


Organizations are drowning in data while struggling to extract meaningful insights. The challenge isn't just the volume, it's the fundamental disconnect between how we store data and how we need to use it. Customer data lives in SQL databases, product documentation sprawls across PDFs, real-time inventory flows through APIs, and historical sales data sits trapped in Excel spreadsheets. Each system speaks its own language, creating silos that prevent us from seeing the complete picture.
This fragmentation creates real business problems. When marketing metrics soar while sales conversion plummets and customer service complaints spike, the inability to connect these data points means organizations can't identify root causes or make informed decisions. The insights that matter most, how marketing campaigns affect customer lifetime value, how product usage patterns predict churn, exist at the intersections of these data silos, remaining invisible when systems can't communicate.

Traditional Retrieval-Augmented Generation follows a straightforward sequence: fetch relevant document chunks based on a query, concatenate them with the prompt, and feed everything to an LLM. While this naive approach works, it introduces significant challenges: (1) low precision, where we’ll have irrelevant but seemingly-related documents, (2) low recall, where not all relevant documents were retrieved, and (3) pipeline inefficiencies that degrade output quality.
The current state-of-the-art is trending toward Modular RAG, a flexible framework of interchangeable, interconnected modules that enables complex workflows. This paradigm shift allows for sophisticated operations like incorporating specialized search modules, employing fine-tuned retrievers, and fusing results from multiple sources. This modularity forms the conceptual foundation for building complex, multi-source retrieval systems.
The straightforward approach to multi-source RAG dispatches queries to all retrieval engines simultaneously: vector search for text chunks, Text-to-SQL for tabular data, graph engines for entity relationships. While architecturally simple, this pattern queries every data source for every request, creating unnecessary computational overhead and potentially overwhelming the LLM with excessive context that dilutes the most relevant information.
Dynamic routing (basically an agentic process) employs a coordinator agent or router as the first step in the workflow. This agent analyzes incoming queries and strategically routes them to appropriate subsystems:
This approach eliminates inefficiencies while ensuring the LLM receives precisely the context it needs.
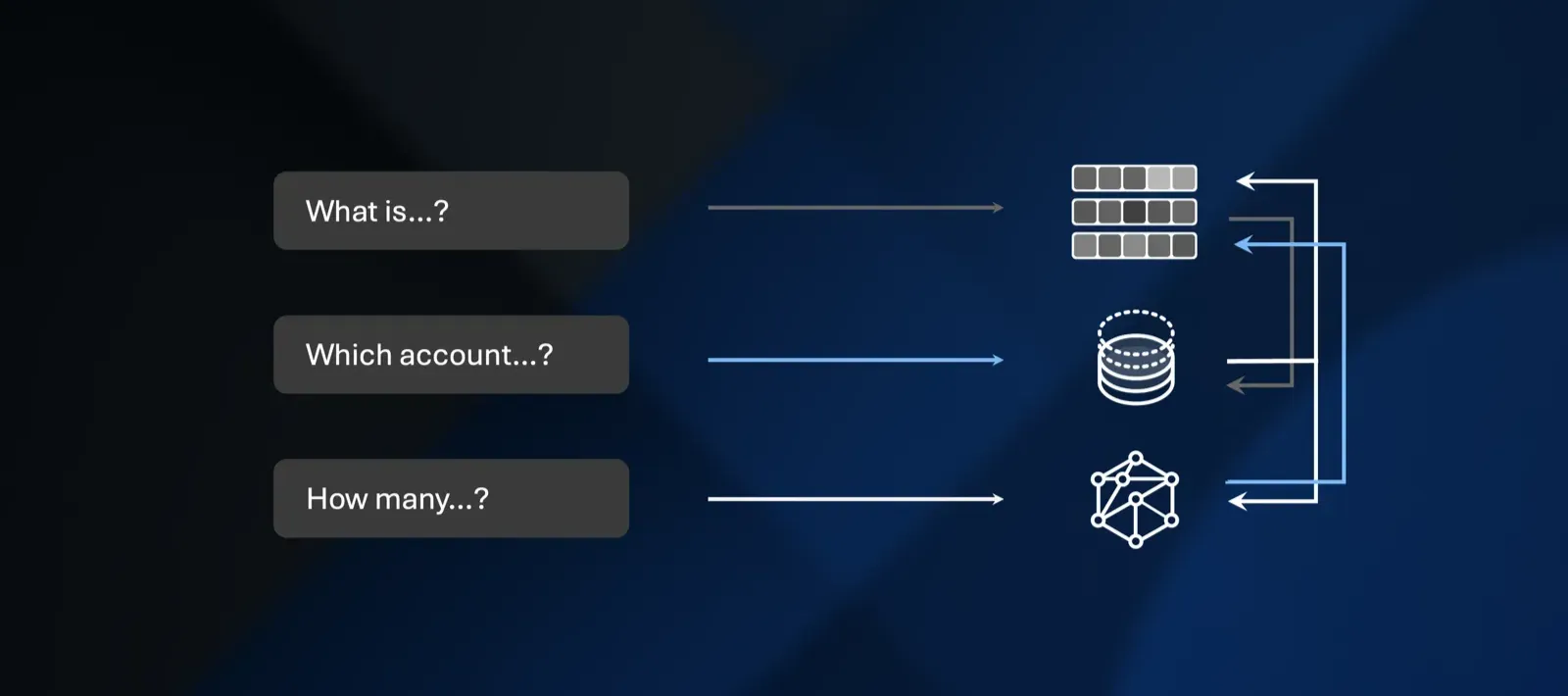
Vector databases power the most widely adopted form of RAG, retrieving qualitative information from unstructured or semi-structured text through semantic similarity. However, vector similarity scores can be opaque, and the process remains susceptible to context poisoning where semantically close but irrelevant documents pollute the results. Throwing everything into a vector database isn't sufficient. Effective retrieval requires multiple storage types, each serving distinct retrieval needs.
Text-to-SQL creates natural language interfaces for complex databases, enabling non-technical users to receive precise, quantitative, data-driven answers. The critical advantage: LLMs can now perform proper arithmetic, counting, and aggregate statistics. Yet challenges remain. LLMs struggle with complex database schemas, particularly those with intricate relationships between numerous tables. This can generate syntactically incorrect SQL or hallucinated queries referencing non-existent tables or columns.
Traditional vector-based RAG treats documents as isolated chunks, neglecting the rich relational knowledge between them. Graph-based retrieval introduces an explainable, structured way to discover context that is relationally crucial rather than relying solely on vector embeddings to determine what is semantically similar.
Consider a corpus of scientific papers: vector search finds semantically similar papers but misses seminal works frequently cited by retrieved documents, even when they use different terminology. A reference graph leverages explicit connections between documents, enabling context-aware retrieval that captures this relational knowledge. This approach can augment RAG queries through graph-weighted re-ranking to prioritize influential or authoritative sources.

Here's the key insight that changes everything: most "unstructured" data is actually structurable. Data contains rich patterns, relationships, and implicit structure that we can extract and leverage. Structurable Data is unstructured data from which a more structured and meaningful representation can be derived.
This isn't merely about parsing tables from PDFs. It's recognizing that legal documents contain citation networks, product manuals have hierarchical relationships, and even conversational data has extractable patterns.
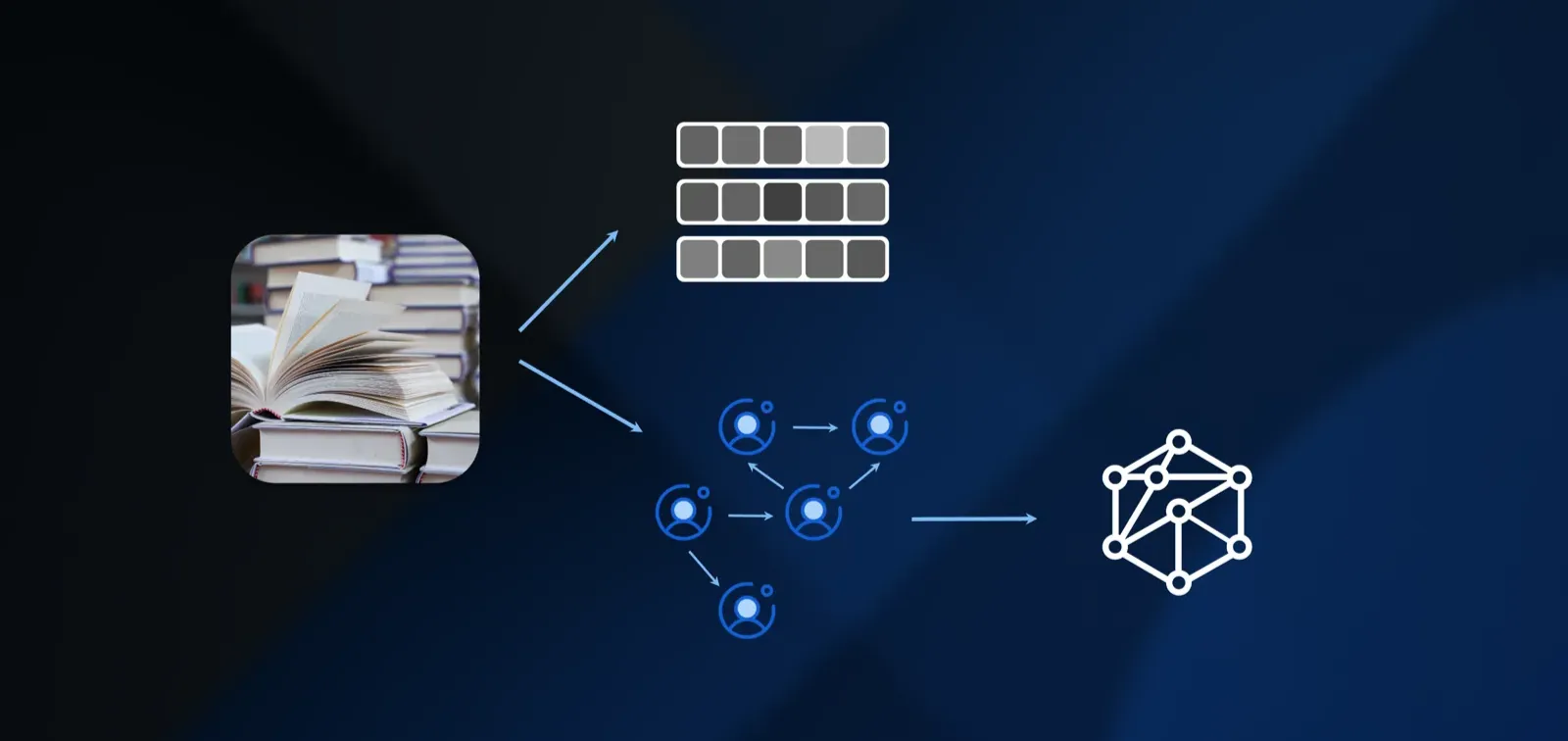
Consider fiction novels, seemingly the pinnacle of unstructured data. Beyond calculating embeddings, we can extract character-character relationships and create graphs. Game of Thrones yields character interaction networks, family lineages, geographical relationships, and plot causality chains. What appears as unstructured narrative actually contains complex relational data ready for mapping and querying.
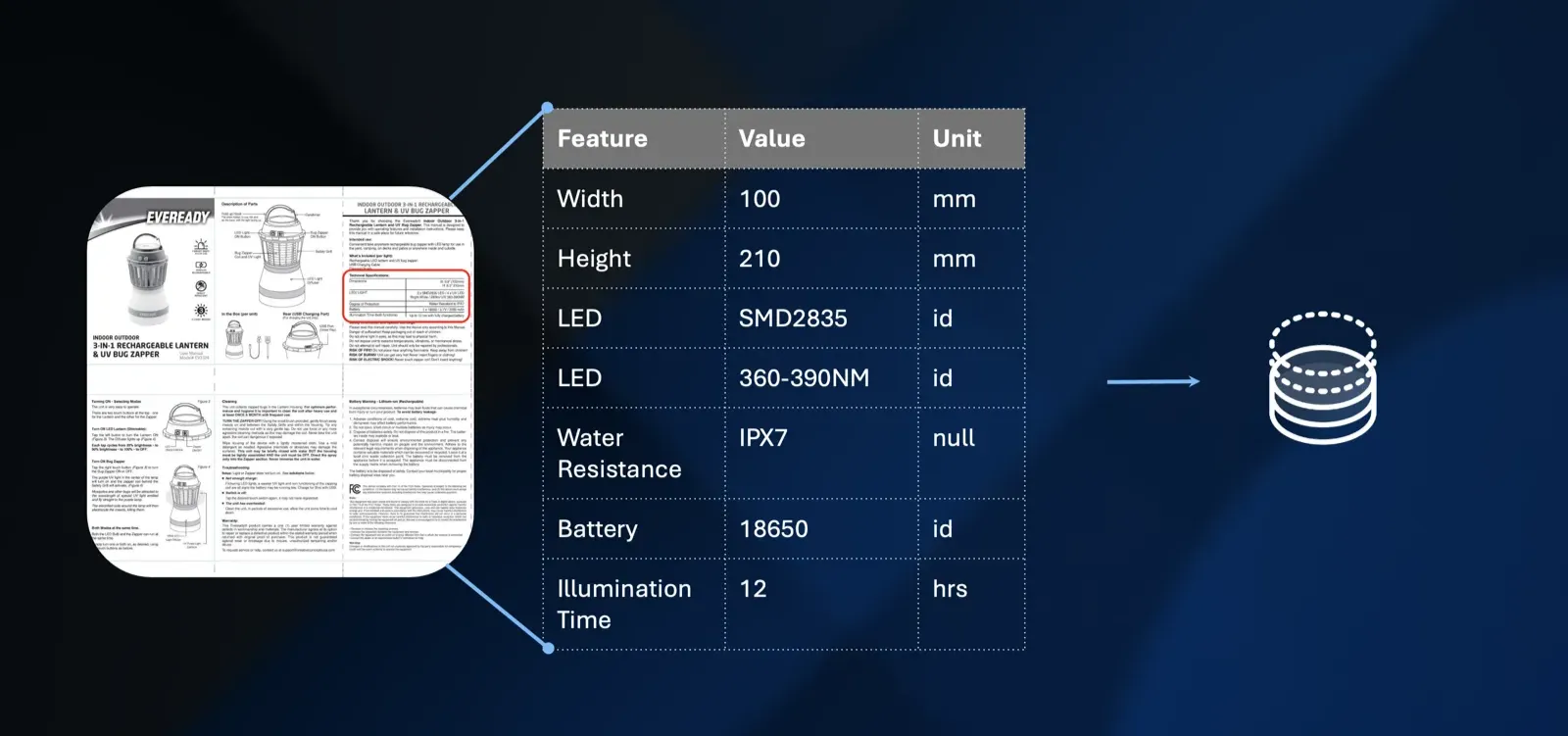
Product manuals reveal another dimension. Buried within unstructured text are structured product specifications: features, values, units, and technical specifications. Through text extraction and OCR where necessary, we transform documents that only support semantic search into data we can filter, sort, and analyze precisely.
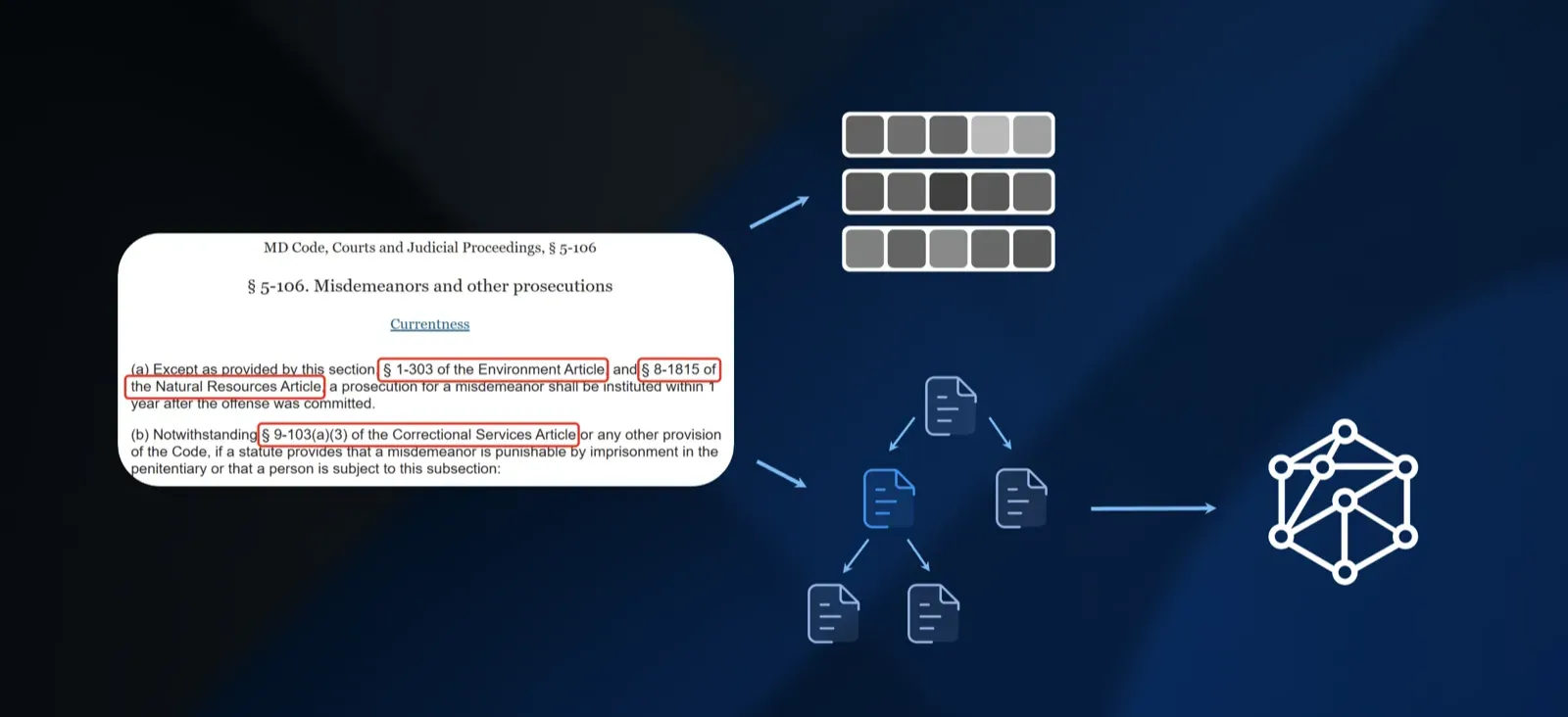
Legal code demonstrates the limitations of pure semantic search. Typical RAG systems find scattered fragments about misdemeanor statutes, environmental regulations, and prosecution timelines but miss the logical connections that give them meaning. It's like receiving a legal argument with all citations stripped out.
Within legal documents, in-text citations and references to other sections create natural graph structures. By building reference graphs from these citations, we retrieve not just semantically relevant documents but also their referenced dependencies, providing complete legal frameworks rather than isolated fragments. When someone queries environmental misdemeanor statutes, the system automatically pulls in referenced Environment Articles and Natural Resources provisions.
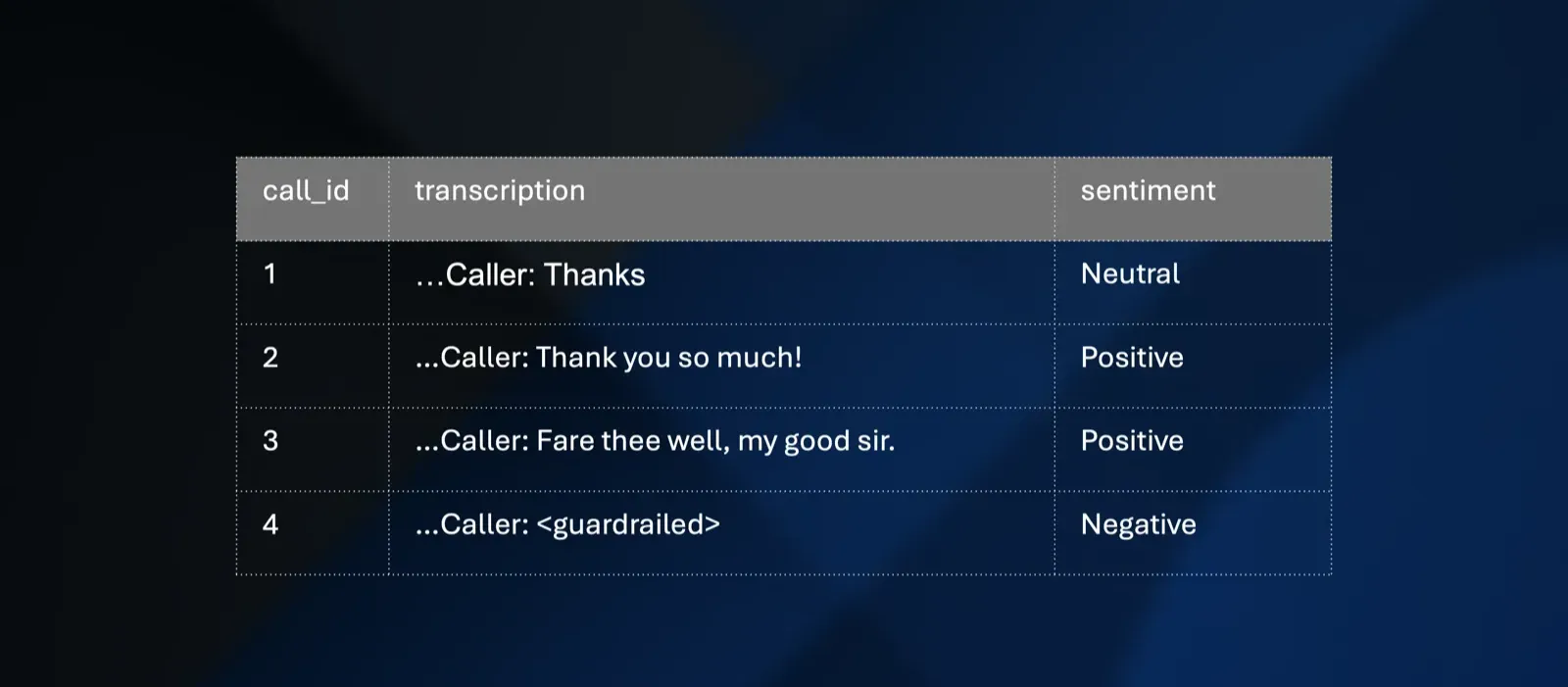
Even formally structured data requires careful consideration. A call transcription table might have organized fields, but a "transcription" column containing raw text provides little analytical value. Only through feature engineering, extracting sentiment, topics, or entities, does unstructured content within structured systems become valuable. The transformation of "Thank you so much!" into a "positive" sentiment classification exemplifies how structure extraction makes data analytically useful.
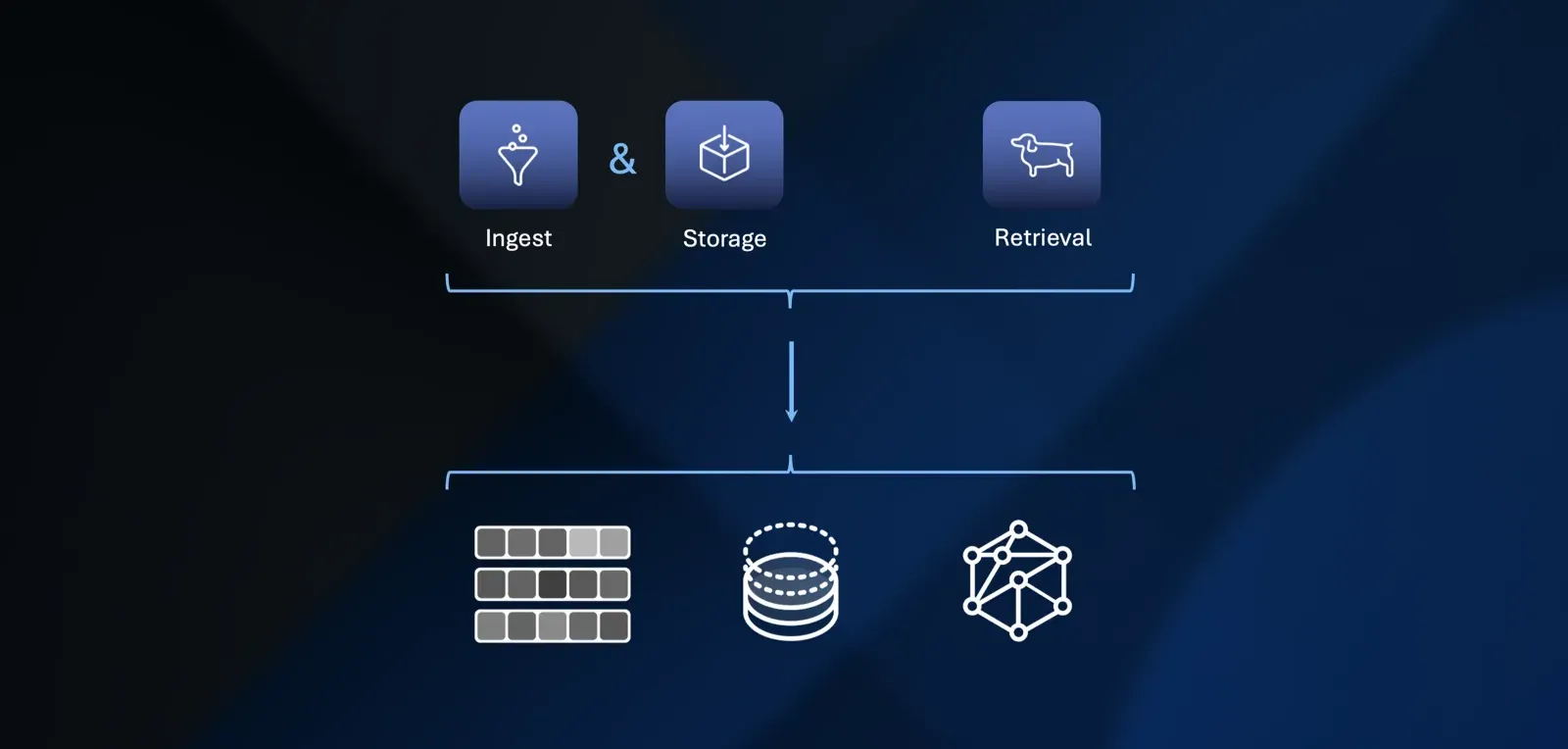
Structure must be considered throughout the RAG pipeline during ingestion, storage, and retrieval. Structured data offers three critical advantages:
To support Hybrid, Modular, Agentic RAG, we identify existing structure and apply structuring techniques during ingestion. We determine optimal storage formats for each data type, automatically create reference graphs from both unstructured and structured sources, and discover hidden relationships that provide richer context for complex questions.
The combination of advanced RAG techniques with systematic structure extraction creates a sophisticated, synergistic architecture. Questions receive complete, accurate answers. Data silos disappear. Context-aware responses avoid misinterpretation and reasoning gaps. Natural language becomes the universal interface for all users.
This approach, which we call Structure Augmented Generation (STAG), transforms how organizations query their data:
Marketing, sales, customer service, and finance data finally work in concert, revealing the complete picture organizations need for informed decision-making.

At Meibel, we're building a runtime platform for generative AI that makes Structure Augmented Generation (STAG) practical for production environments. STAG represents one of our core insights in the broader picture of running AI reliably in production: that the path to reliable, powerful AI systems lies not in treating data as either structured or unstructured, but in recognizing and extracting the latent structure that exists everywhere.
Our runtime confidence framework relies on this Structure Everything ethos, handling the complexity of multi-database orchestration, intelligent query routing, and structure extraction at scale, resulting in a wholistic platform for confident AI implementation that allows engineering teams to focus on building applications rather than infrastructure. By providing the foundational layer that understands how to find, extract, and leverage structure across all data types, we're helping companies build production AI pipelines with confidence.
The technical barriers between questions and insights disappear when the runtime understands that every piece of data, from novels to databases to legal documents, contains structure waiting to be unlocked.
Ready to start your AI journey? Contact us to learn how Meibel can help your organization harness the power of AI, regardless of your technical expertise or resource constraints.

Spencer Torene serves as Principal Research Scientist at Meibel, where he shapes the platform's confidence scoring and runtime evaluation systems. He holds a Ph.D. in Computational Neuroscience from Boston University (2010-2017) and brings expertise in machine learning and AI research. Prior to Meibel, Spencer spent over six years at Thomson Reuters Special Services, progressing from Senior Research Scientist to Manager of Research and Development (2018-2024), where he led AI and machine learning R&D initiatives. He earned his Bachelor of Science in Computer Science from the University of Maryland (1999-2004) and completed the Leadership and Management Certificate Program at Wharton Online (2021).
REQUEST A DEMO
See how Meibel delivers the three Cs for AI systems that need to work at scale.

