


Adapted from Berk Ekmekci’s talk at AI4 2025 on Wednesday, August 13, 2025
When working with modern AI techniques, understanding and working with the value of data goes beyond traditional measures. Just as important as what structures your data has and what structures you need it to have, is what structures your data can be transformed into. Here at Meibel, we've come up with a term for this: Structurable Data.
Structurable Data is unstructured data from which a more structured and meaningful representation can be derived.

The value of this way of thinking spans across multiple domains. In manufacturing and industrial industries, you might have your starting data be a constellation of very many different document types coming from different places. And they might be very disorganized. You might have scans of documents. Of images, you might have a product specification Excel worksheet that is the only place where certain information for a supplier comes in. The challenge is bringing all that into a unified view.
In the clinical research auditing space, the problem is a little bit different. You might have data structures that are a bit too specific or too complex, highly specific codes that might mean the same thing in multiple documents. Your job might be to structure it and restructure it in such a way that the underlying information becomes unified and accessible.
In defense logistics and mission readiness, there is a similar analog, but one that spans multiple levels of granularity. Information that is highly specific needs to be available alongside information that is giving a top level view.
If you think of the variety of data structures that are the starting data structures for each of these domains and consider how varied and distant they can seem from the target data structures, it's easy to think about as being overwhelming or being inherently messy.
“Messiness of your data is something that is not only a function of what that data is and the variety of places you get it from and store it, but also your ability—or in some cases, inability—to structure it in a way that's meaningful.”
And that's what we're talking about: taking the information you know is there, the value you know is there, and bringing it all together.

While modern AI structuring techniques are very powerful, they do build on a foundation and history of existing techniques for structuring and restructuring your data. It's nothing new, and it helps to set the stage by taking a brief look to the past.
The 1990s and 2000s was a world of relational databases and tabular data. SQL was gaining a lot of popularity, Microsoft Excel was becoming a household name, and Microsoft Access and similar tools were trying to span the world between those tools. But with the tooling requiring highly structured data to operate, the threshold for machine usability was quite high. Similarly, in order to get your data into that level of structure, the options were relatively limited. It had to be either manually structured and restructured, or you had rigid data pipelines and software methods to bring a certain input into a certain output.

Some of that changed in the 2010s in two major ways.

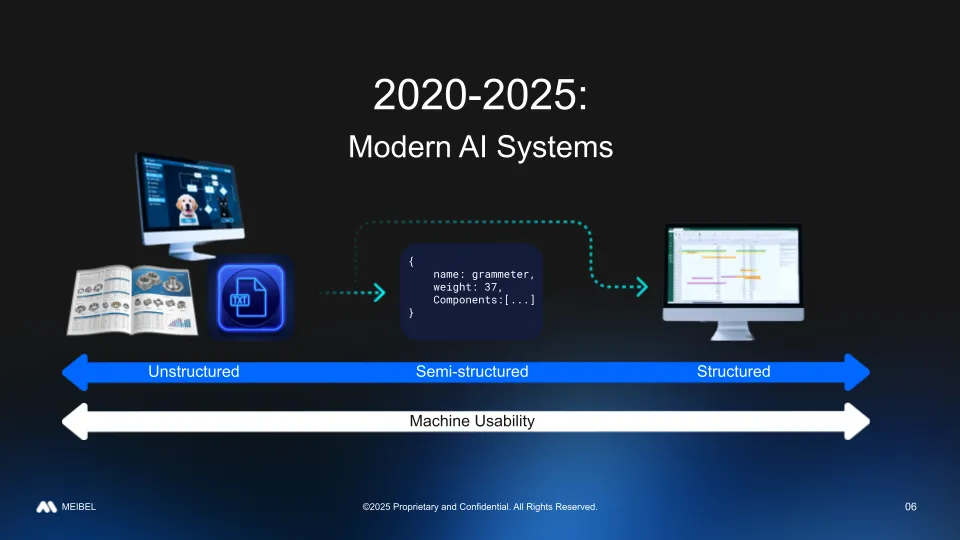
Today, we're seeing all of this much more accelerated. With modern AI systems, structurability runs this full spectrum of structure: unstructured all the way to highly structured. Furthermore, machine usability, in terms of the systems that do analysis and retrieval, can begin at multiple points along the spectrum of structure as well.
So the key question as a practitioner then is: “How do I go about doing this? I've got so many possibilities, so many options, so much flexibility. What are the guiding principles I should use?”
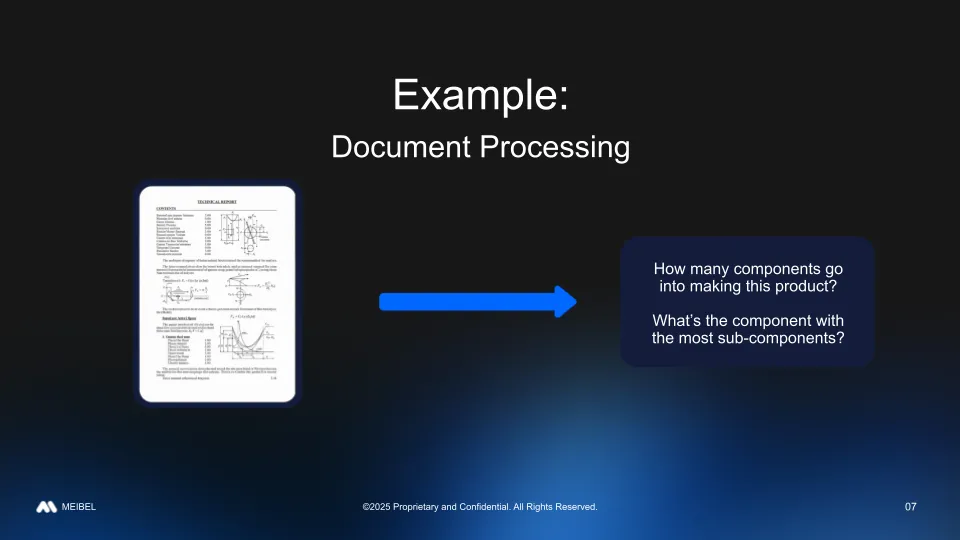
Consider a document processing example where we have some technical report documents and we want to get to certain answers about our manufacturing process based on those documents such as:
In a traditional approach to this, there would be a specific ETL process configured to load this specific document type into a structured representation, and then a predefined algorithm analysis that takes that structured representation and answers specific questions.
With the rigidity of these algorithm analyses, each question would be its own pipeline for analysis. You can think of that as being as simple as a SQL query, but it can get much more complicated based on the type of analysis that you're doing. The advantage here is this is a deterministic system; it runs the same way each time, and once you have it working, you can verify that it's working pretty easily.
At the same time, it’s quite rigid. If you have any changes or differences in your input documents, you need to adjust your ETL process. You need to ask yourself the question, “Is that rigid structure I have in the middle still relevant? Do I need to change that?” If you wanted to add a new question to answer, not only do you need to change the analysis, but ask yourself the question “Does my structure and ETL process support this?”

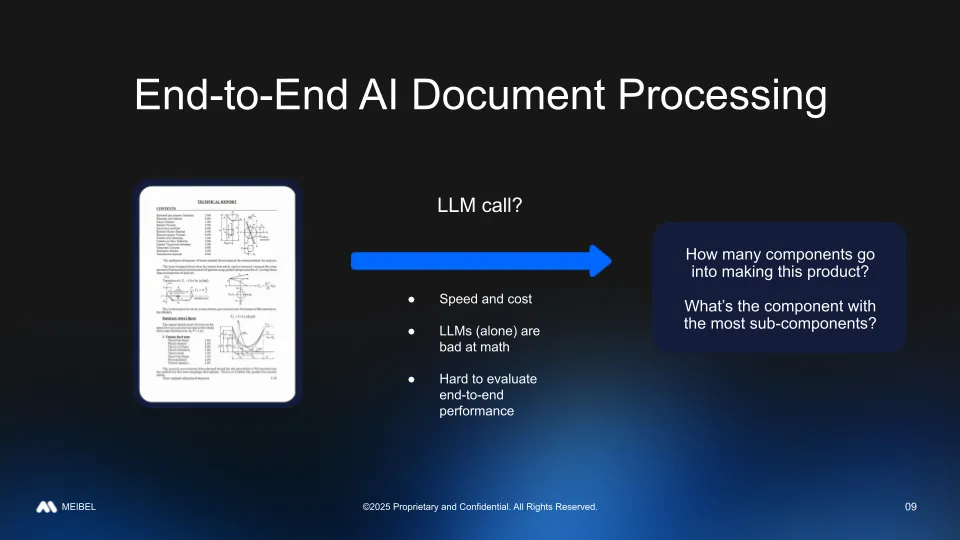
Given that we have such powerful LLMs, can't we just replace this whole thing end-to-end with an LLM call? From the perspective of flexibility and ease of setup this idea is very attractive, getting the process working and integrating for the first time. However, it has some major drawbacks that make it infeasible or less feasible.
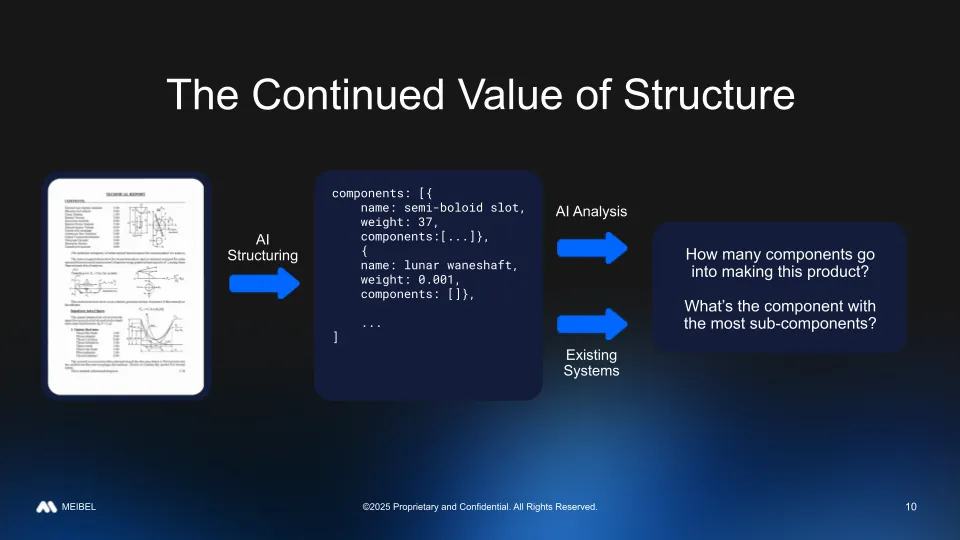
An that maximizes the benefits of each of these above ways of working while minimizing their downsides is one that makes the most of the structurable nature of data. AI structuring as a first step allows for the conversion of input documents into a structured (and restructurable) intermediate representation. This representation then serves as a key checkpoint in the process, that is not just relatively human readable, understandable, and verifiable, but also very machine friendly. From there, you can use AI analysis to get to the answers to your questions quite flexibly and dynamically while maintaining the reliability of the chosen intermediate representation.
A second major benefit to working with structurable data in this way is that you retain access to a lot of the value of your existing systems. All of your existing analysis pipelines are built to work with a certain structure of data. If you choose to move into that structure, perhaps in addition to other structures, you get all the value of the prior established structure going forward. That's not just business value or value in terms of engineering time saved to not have to rebuild a certain process; it also means that if you're in a regulated or restricted industry, you can have confidence that everything that has been approved, vetted, and verified downstream of that structure is working as intended and now the AI structuring piece can be the focus of your review and validation.
What happens if we have not just one type of input document, but rather several input documents of different types? Is that structure that we chose for our original technical documents the best representative structure? Is it a unifying model? If we had chosen a different starting point or document type to begin building out our use-case, could we have gotten a better overall structure?
These are all natural questions that follow from a successful first implementation of an AI workflow focusing on Structurable Data and are essential to thoughtful implementation at larger scope. But more broadly, how do we evaluate the quality of a structure overall? This is an important question with a nuanced answer: while all data is structurable, not all structures are useful.
This is a direct consequence of how you’re faced with an infinite choice in terms of the structures you can choose. While this is encouraging in its possibilities, it’s also a little bit daunting because infinity can be an intimidating concept to think about.
There's some good news and bad news in this path that you need to develop in terms of choosing data structures to target in your structurable data pipelines.



So at this point you might be thinking to yourself, well, doesn’t this run opposite the findings of The Bitter Lesson? It seems like any AI talk in 2025 wouldn’t be complete without a reference to The Bitter Lesson, so let’s take a moment to talk about it.
For those unfamiliar, it was a 2019 essay by AI researcher Richard Sutton. To summarize, it's the idea that when you take a historical look back at AI research over the past several decades, specific methods that try to encode an understanding of how a human might go about solving a problem or methods or techniques that a human might have for approaching a problem eventually always get outcompeted and outperformed by general systems that give a learning system the framework in which we evaluate performance and allow it to freely learn each way of solving the problem. So in the long run, generalized systems that are unguided in how they go about the task and simply evaluated on their ability to perform the task, win on performance.
So why are we talking about these checkpoints of structured data?
Well, the key thing there is that the Lesson doesn't give a specific timeline. So it might be for a given problem that there is two years, five years, maybe just one year in between the time where you have a certain specific method until the generalized method catches up and outperforms it. In terms of business realities, you can get a lot of value out of your data pipelines in that timeframe. That can create a lot of very real benefit to you, your customers or users, the people that you serve.
Another piece that I want to draw attention to is that when you're choosing that intermediate structure for your AI workflows, you're not saying how to structure at that point or how to analyze from that structure. You're giving an agreed upon checkpoint that you and your AI systems can use together and verify that what you're doing is working well.

The messiness of your data isn’t just about what it is or where it comes from. It’s about your ability to structure it meaningfully. Successful structurable data workflows are built on creating structured checkpoints that are both human-readable and machine-friendly, allowing you to leverage existing systems while maintaining the flexibility of AI systems. Doing this most effectively requires recognizing that while all data can be structured, not all structures are useful.
The near future of AI analysis brings together multiple data sources housing useful structural forms with intelligent retrieval and analysis that selects the right structure for each problem. This moves the search away from a one-size-fits-all solution, and instead toward a dynamic system that uses the structurability of data flexibly. That’s what we’re building at Meibel.


This post is based on a talk given at AI4 2025. Slides are available here. A recording of the presentation will be available soon. For background on structured data concepts, see Meibel's introduction to Structurable Data.
For more information about implementing structurable data approaches in production systems, visit meibel.ai.
Ready to start your AI journey? Contact us to learn how Meibel can help your organization harness the power of AI, regardless of your technical expertise or resource constraints.


REQUEST A DEMO
See how Meibel delivers the three Cs for AI systems that need to work at scale.

